Best Fit combines algorithmic challenges with AI-assisted reasoning analysis—
capturing the "how", not just the "what".
We screen for syntax. We hire for problem solving.
Standard technical assessments are often passed or failed on edge cases, missing the nuance of engineering trade-offs, optimization logic, and communication style.
false negatives in automated screening dependent on exact output
Engineering Hiring Report, 2024
average time spent on take-home tests that are never reviewed
Candidate Experience Survey
of engineering managers cite 'communication' as the top missing skill
State of Tech Hiring, 2023
signal gained on a candidate's trade-off analysis in LeetCode style tests
Assessment Gap Analysis
higher offer acceptance rate when the process feels like a conversation
Recruitment Benchmarks
more likely to identify senior-level thinking with open-ended prompts
Lyrathon Internal Data
"Wearefilteringoutgreatengineersbecausetheydon'tthinklikeacompiler.Weneedthemtothinklikeengineers."
Thesignalisnotthe code.
Itisthe reasoning.
Correctness is the baseline, not the ceiling.
We shifted the evaluation metric. Instead of just passing test cases, we reward the explanation of *why* a solution was chosen and what trade-offs were made.
AI as a mirror, not a judge.
LLMs are great at conversation but inconsistent at grading. We built a system where deterministic tests control the score, while AI captures the qualitative 'how'—without hallucinating results.
Designing the system, not just the UI.
I entered the hackathon as a designer, but influencing fairness meant defining system boundaries. I ended up making full-stack decisions on database schema and evaluation prompts.
48 hours. One goal.
No mockups.
Constraint
Lyrathon 2025: Build something that improves the candidate experience.
Prototype
Next.js + Postgres + OpenAI API. Rapid iteration on prompt engineering.
Refine
Testing against edge cases: what if the candidate is right but the AI disagrees?
Ship
Live demo with real-time streaming analysis and deterministic scoring.
Scroll to watch the concept crystallise
Best Fit, Assessment with depth.
AI guardrails. Human insight.
A dual-layer evaluation engine. Layer 1 runs unit tests for objective truth (does the code work?), while Layer 2 analyzes the candidate's written walkthrough for grasp of complexity and trade-offs.
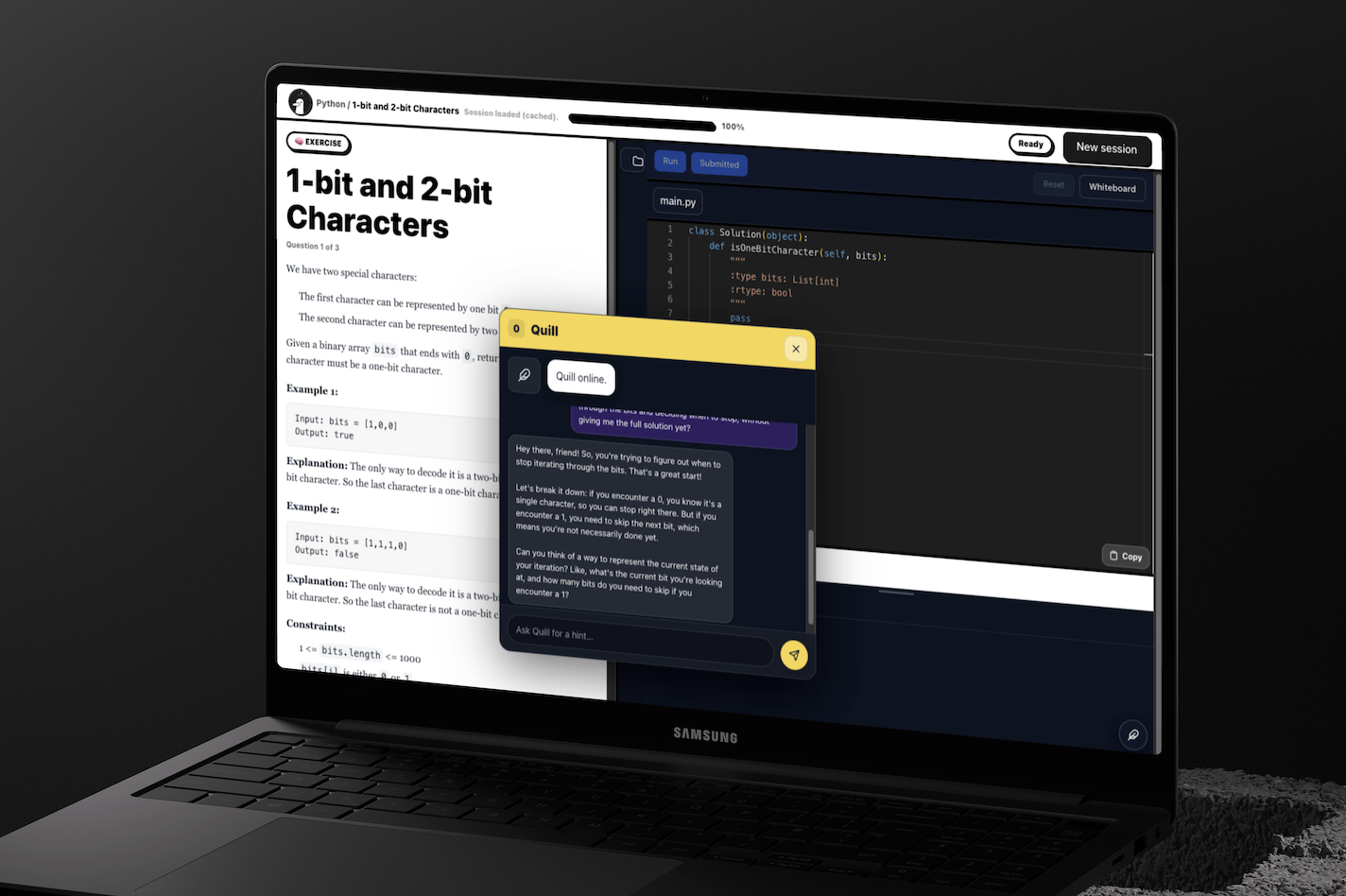
Start Challenge Screen
Candidates begin solving the challenge while Quill prompts them to reflect on their approach, capturing reasoning that goes beyond the final code submission.
Start Challenge Session
Candidates start with a lightweight onboarding experience that frames the assessment as a challenge rather than a test.
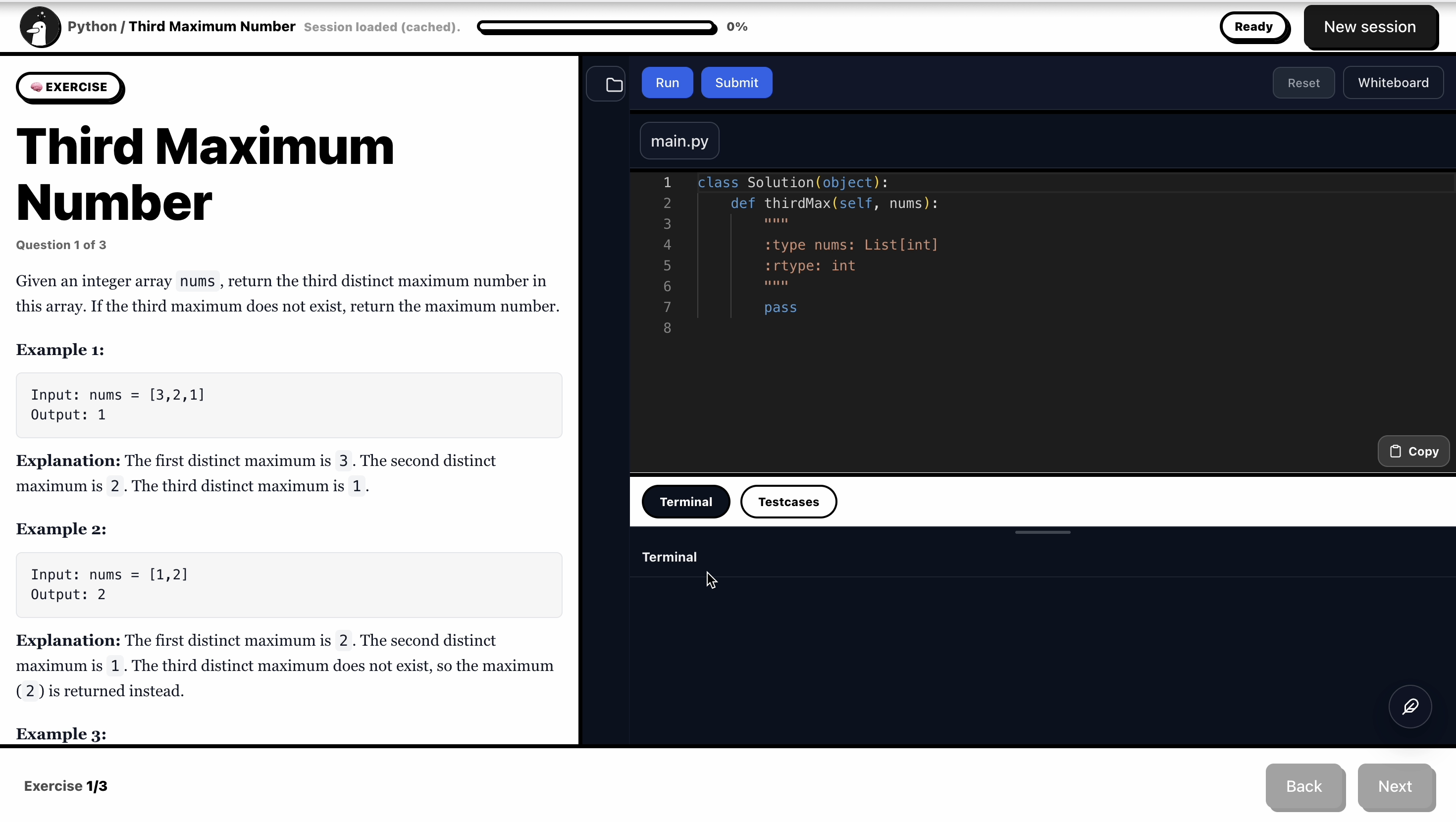
Coding Environment
Candidates solve problems inside an integrated coding environment while the system captures both execution results and reasoning signals.
Quill AI Interaction
Quill acts as a conversational layer that captures reasoning before and after coding.
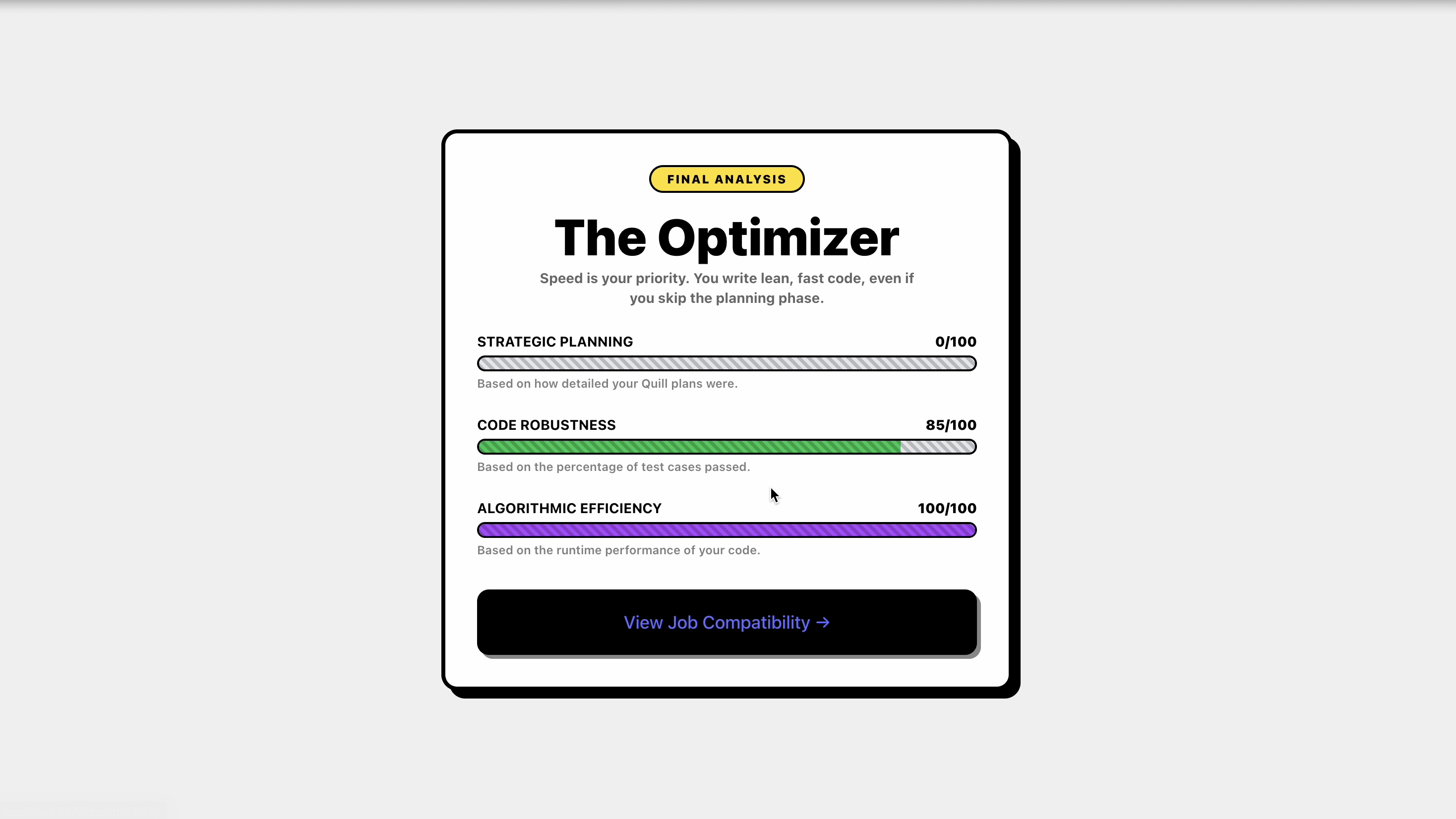
Session Results
After each session, candidates receive structured feedback instead of a binary pass/fail result.
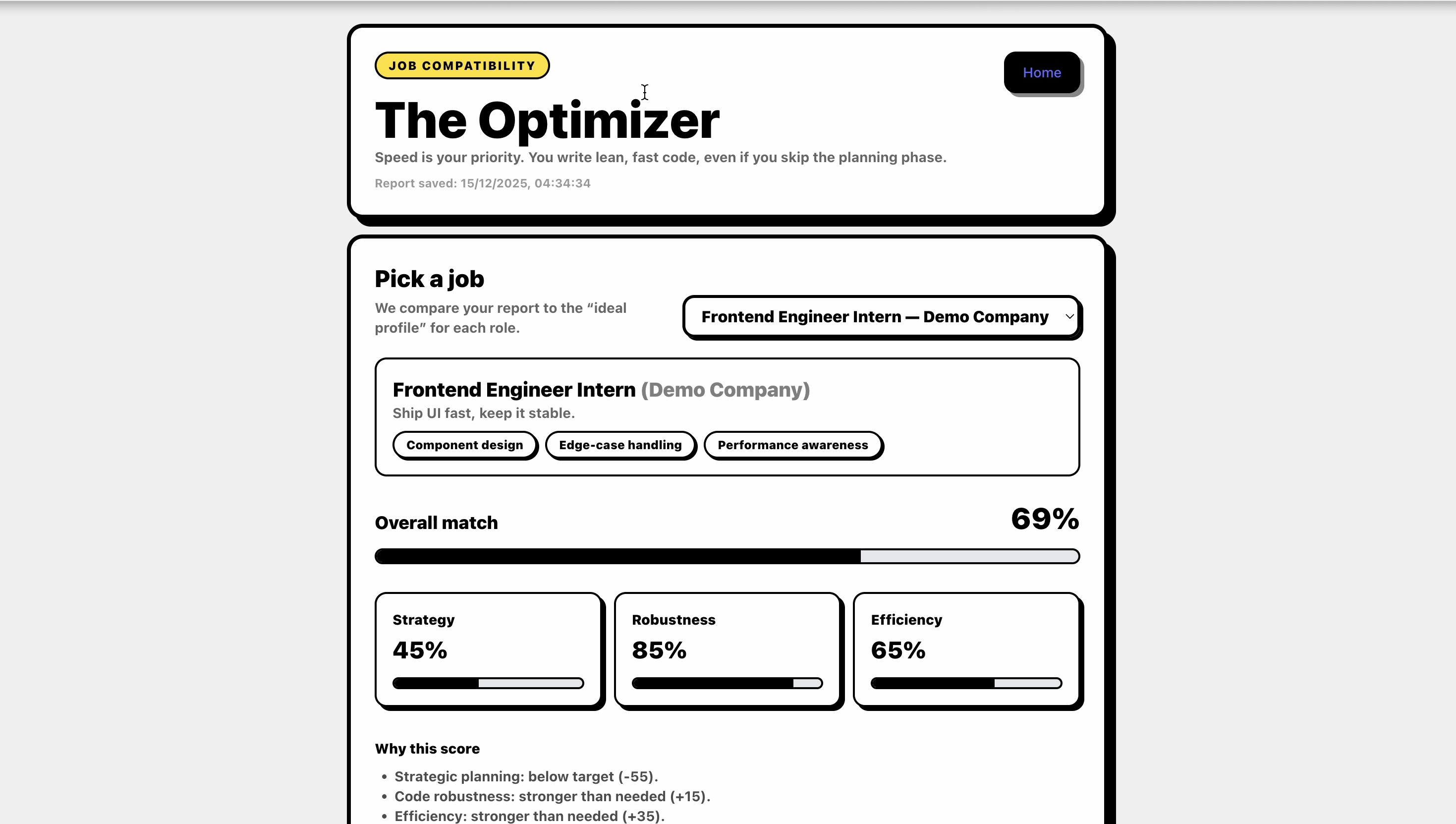
Job Compatibility View
Signals from the session are mapped to role profiles to show where a candidate’s strengths align.
Designing for fairness means
designing the whole system.
We learned that "fairness" isn't a UI toggle. It lives in how we prompt the model, how we weigh the scores, and where we draw the line between machine opinion and human judgment.